Advances In The ZIO 2.0 Scheduler
ZIO 2.0 advances concurrent Scala programming through multiple enhancements including performance gains, improved developer experience, integrated logging and metrics support, and a reimagined streams architecture.
This article concentrates specifically on the new fiber-aware scheduler driving ZIO 2.0 performance improvements. The discussion covers scheduler fundamentals, implementation importance, operational mechanics, common implementation risks, and how ZIO's design avoids these pitfalls.
Schedulers
Functional effect systems enable highly composable, elevated code patterns. Example fiber execution across 100,000 logical processes:
import zio._
for {
ref <- Ref.make(0)
fibers <- ZIO.foreach(1 to 100000)(_ => ref.update(_ + 1).fork)
_ <- ZIO.foreach(fibers)(_.join)
value <- ref.get
} yield value
While this high-level expressiveness matters, runtime performance depends entirely on the scheduler's capability to manage countless fibers across a constrained thread pool.
Machine threading constraints typically match core counts—roughly 8 cores locally or potentially 256 on servers. The scheduler must accomplish two essential objectives:
- Execute all submitted work
- Maximize performance
Single Global Queue Approach
ZIO 1.0 implemented a straightforward single global queue model:
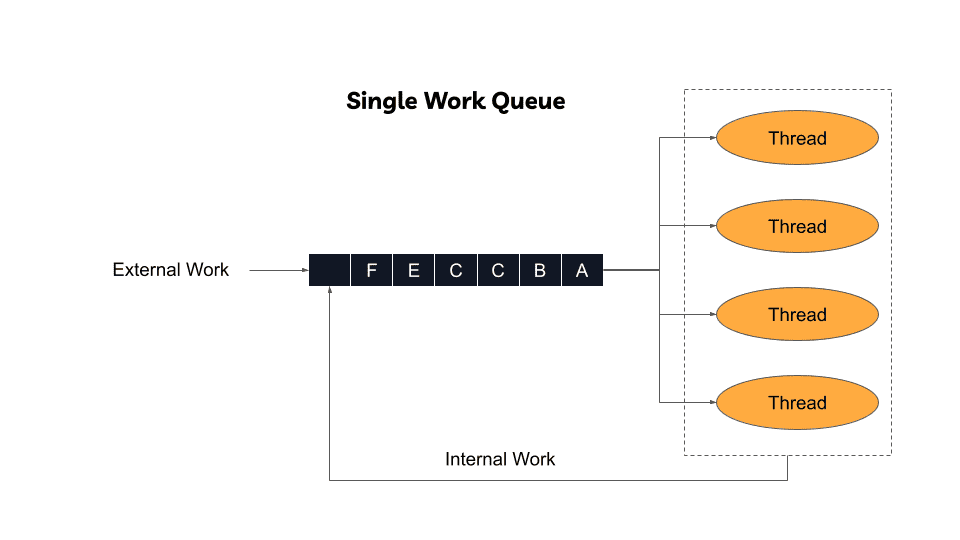
New work submissions append to queue endings. Worker threads continuously extract and execute work units.
Correctness advantage: This approach guarantees eventual task completion—all submissions reach execution.
Performance disadvantages:
- Single queue creates contention bottlenecks when numerous workers simultaneously offer/take work
- Cache locality suffers—forked fiber work executes on random threads, losing related data already cached
Local Queue Approach
Each worker maintains individual queues:
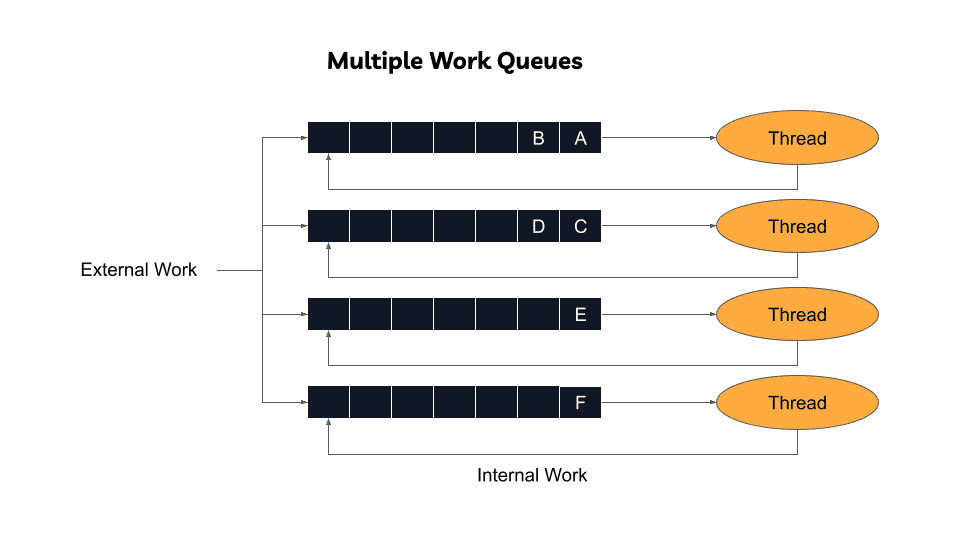
Performance advantages:
- Eliminates global contention entirely
- Maximizes cache locality—forked fibers always run on originating threads
Fairness problem: Workload imbalances emerge. One worker's queue fills while another remains idle, potentially leaving cores unused.
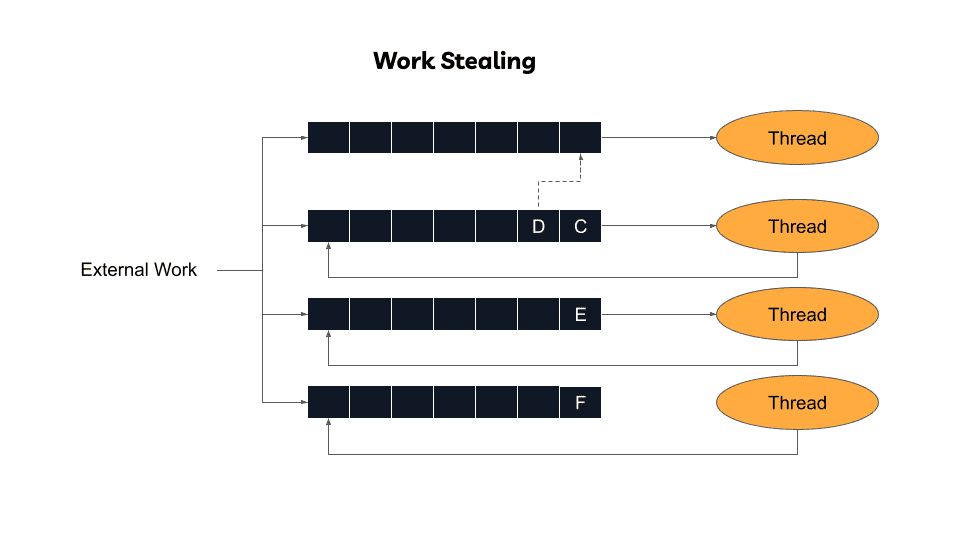
Work-Stealing Hybrid (ZIO 2.0)
ZIO 2.0 combines local queues with work stealing capabilities:
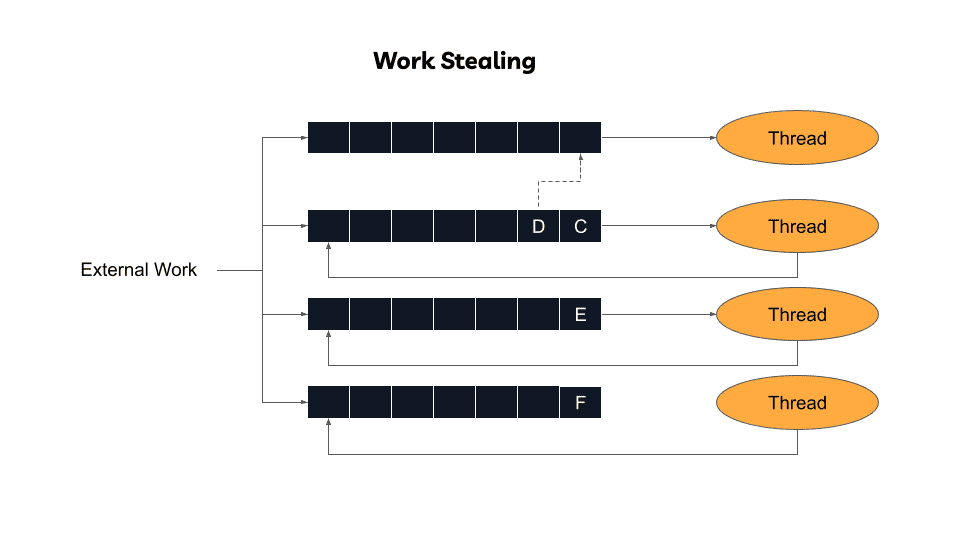
Workers primarily execute local queue tasks, minimizing contention and preserving cache benefits. When local queues empty, workers "steal" from others' queues, preventing idle cores during uneven load distribution.
This design was inspired by the Tokio project—a high-performance Rust async runtime.
Fast and Correct
Work-stealing introduces substantially greater complexity than pure approaches. Key implementation questions emerge:
- Should local queue sizes be limited? Where does overflow work go?
- When should workers signal work availability to other workers?
- When should stealing attempts occur or global work be accessed?
These decisions enable performance gains but create catastrophic pitfalls. Incorrect implementation can produce "fundamentally unsound" schedulers with "catastrophic implications" for runtime correctness.
Cats Effect 3 Deadlock Example
Cats Effect 3 implements local and batched queues. When a worker's local queue fills, half the tasks move to the batched queue. Workers only check the batched queue after exhausting local work.
This seems logical initially—why revisit batched work before emptying local queues? However, it violates a critical invariant: all submitted work must eventually execute.
Consider workers continuously generating and executing new work while checking state to determine continuation. Workers might never check the batched queue, potentially deadlocking if that queue contains work signaling execution termination.
This concrete example deadlocks Cats Effect 3:
import cats.effect._
import cats.implicits._
object CatsScheduling extends IOApp {
def run(args: List[String]): IO[ExitCode] =
io.as(ExitCode.Success)
def yieldUntil(ref: Ref[IO, Boolean]): IO[Unit] =
ref.get.flatMap(b => if (b) IO.unit else IO.cede *> yieldUntil(ref))
val io: IO[Unit] =
for {
n <- IO(java.lang.Runtime.getRuntime.availableProcessors)
done <- Ref.of[IO, Boolean](false)
fibers <- List.range(0, n - 1).traverse(_ => yieldUntil(done).start)
_ <- IO.unit.start.replicateA(200)
_ <- done.set(true).start
_ <- IO.unit.start.replicateA(1000)
_ <- yieldUntil(done)
_ <- fibers.traverse(_.join)
} yield ()
}
One fiber per core continuously checks whether a Ref equals true while yielding. Another fiber sets the Ref to true, yet this fiber never executes—causing permanent deadlock despite fairness guarantees from the cede operator.
ZIO 2.0 Solution
The ZIO 2.0 fiber-aware scheduler achieves high performance through relatively straightforward implementation. It maintains a single global queue and workers periodically check it after executing defined work iteration counts, preventing unsoundness and deadlock scenarios.
The equivalent ZIO 2.0 code:
import zio._
object ZIOScheduling extends App {
def run(args: List[String]): ZIO[ZEnv, Nothing, ExitCode] =
io.exitCode
def yieldUntil(ref: Ref[Boolean]): UIO[Unit] =
ref.get.flatMap(b => if (b) ZIO.unit else ZIO.yieldNow *> yieldUntil(ref))
val io: UIO[Unit] =
for {
n <- ZIO.succeed(java.lang.Runtime.getRuntime.availableProcessors)
done <- Ref.make(false)
fibers <- ZIO.foreach(List.range(0, n - 1))(_ => yieldUntil(done).forkDaemon)
_ <- ZIO.unit.forkDaemon.replicateZIO(200)
_ <- done.set(true).forkDaemon
_ <- ZIO.unit.forkDaemon.replicateZIO(1000)
_ <- yieldUntil(done)
_ <- ZIO.foreach(fibers)(_.join)
} yield ()
}
This program terminates correctly and instantly.
The team continues optimizing while prioritizing correctness over synthetic microbenchmark improvements. Such optimizations rarely translate to real-world gains and introduce risks of catastrophic failures.
Summary
The fiber-aware scheduler represents one component of ZIO 2.0's comprehensive improvements. Additional enhancements include optimized blocking operation handling, accelerated unsafeRun operations in mixed codebases, and a finely tuned runtime.
ZIO 2.0 also introduces ergonomic improvements benefiting diverse developers, automatic side-effect management, integrated logging and metrics, enhanced tracing, refined streams, and high-performance concurrent structures like ZHub.
The fiber-aware scheduler demonstrates how thoughtful design balances performance with reliability, delivering speed without sacrificing correctness.